EEEM071: Module-5 3D Vision
Updated: April 5, 2023
Hi, this is Pinaki. I prepared the following notes for an MSc. course on 3D Vision where I am a TA. While you can read this material if it helps you, I strongly encourage you to check the references and original papers (in the bibliography). I believe you should learn directly from the people making the inventions and not third-party like me.
Introduction
3D vision plays an important role in various domains and includes applications in autonomous driving, robotics, remote sensing, medical treatment, augmented reality, design industry, among many others.
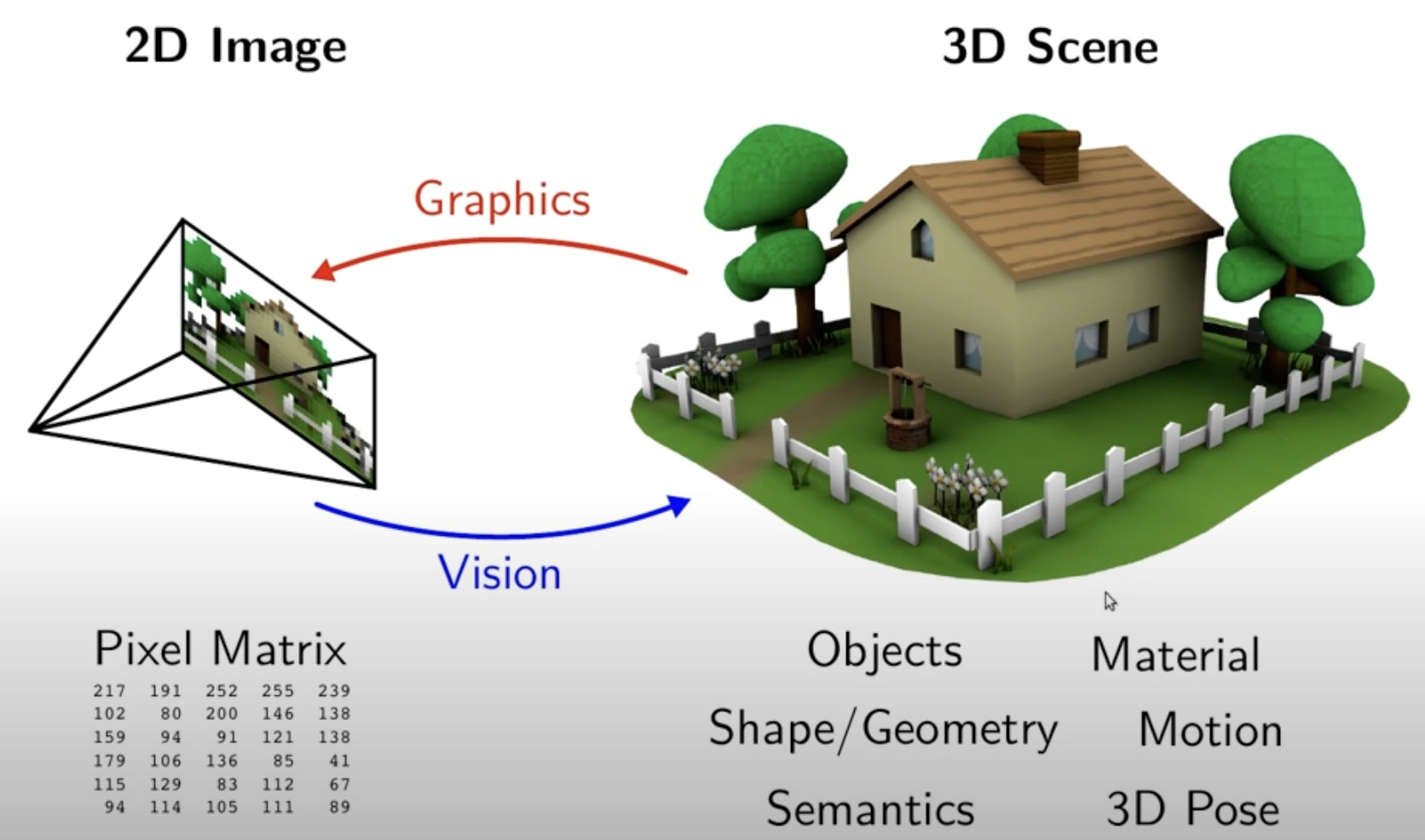
In computer graphics, given the 3D scene composed of objects, materials, certain semantic poses, and motion, we are concerned with rendering a photorealistic 2D image of the scene. In computer vision, we are trying to solve the inverse problem (aka. inverse graphics), where we only see a 2D image (a raw pixel matrix) and a lot of information from the original 3D scene has been lost through the projection process. Hence, computer vision is an ill-posed inverse problem as (1) many of the 3D scenes yield the same 2D image, and (2) additional constraints (knowledge about World) are required to solve the ill-posed inverse problem. These constraints can come from engineering principles, first principles about the world, or from large datasets where this knowledge has been acquired.
In this lecture series, we shall:
-
Describe a few 3D representations, their benefits and limitations.
-
Applications of implicit representations for 3D vision.
-
Applications of inverse rendering approach like NeRF.
3D Representations
Multi-view Representation – a 3D shape can be represented as a set of 2D images captures from different viewpoints. Compare to other 3D representations, this representation is relatively efficient due to having one less dimension where one can exploit 2D learning methods for 3D analysis. Additionally, capturing such data is readily obtainable using 2D cameras, as opposed to 3D sensors which are more expensive and less common. Although multi-view representation targets easier 2D processing, one can also extract 3D information and process it in 3D via stereo vision along with triangulation of the camera rays.
Depth Images – a depth image provides the distance between the camera and the scene for each pixel. This data can be easily acquired using depth sensors such as Kinet, among many others. Depth images can also be obtained from multi-view or stereo images, in which a disparity map is calculated for every pixel within an image. Since a depth image is captured from one viewpoint, it does not describe the whole object geometry – objects are seen from one side only. Nevertheless, since many 2D algorithms can be directly employed on such structured data, using this representation benefits from the great advances in 2D processing.
Point Cloud – a point cloud is a set of vertices in 3D space, represented by their coordinates along the x, y, and z axes. Such data can be acquired from 3D scanners e.g., LiDARs, or RGB-D sensors, from one of more viewpoints. Colour information captured by RGB cameras can be optionally superimposed on the point cloud as additional information. Unlike images that are usually represented as matrices, a point cloud is an unordered set. As such, processing such data entails a permutation invariant method so that the output does not vary with different ordering of the same point cloud.
Voxels – a voxel representation provides information on a regular grid in 3D space. The voxel (volume element) is analogous to pixels (pictures/pix elements) on which information of 2D images is placed. The information provided at every voxel includes occupancy, colour, or other features. A voxel representation can be obtained from a point cloud through the process of voxelisation, which groups all features of 3D points within a voxel for later processing. The structured nature of 3D voxels allows the processing of such information similar to 2D methods, e.g., convolutions. However, voxel representation is usually sparse as it contains a lot of empty volumes corresponding to space around objects. Additionally, since most capturing sensors collect information on object surfaces, object internals is also represented by empty volumes.
Mesh – a mesh is a collection of vertices, edges, and faces (polygons). The elementary component of the polygon is a planar shape defined by connecting a group of 3D vertices. Compared to the point cloud which only provides vertices locations, a mesh includes information on the object surface. Nonetheless, processing the surface information directly using deep learning methods is not straightforward, and many techniques resort to sampling points from the surface in order to transform the mesh represented into a point cloud.
Point Cloud triangulation using Marching Cubes
Reference
-
Computer Vision – Andreas Geiger https://youtube.com/playlist?list=PL05umP7R6ij35L2MHGzis8AEHz7mg381_
-
J. Lahoud, J. Cao, F.S. Khan, H. Cholakkal, R.M. Anwer, S. Khan, M.H. Yang. 3D Vision with Transformers: A Survey. arXiv:2208.04309, 2022.
Bibliography
[1] J. Devlin, M.W. Chang, K. Lee, K. Toutanova. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In NAACL-HLT, 2019.
[2] Y. Liu, M. Ott, N. Goyal, J. Du, M. Joshi, D. Chen, O. Levy, M. Lewis, L. Zettlemoyer, V. Stoyanov. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv:1907.11692, 2019.