EEEM071: Module-5 Cross-Modal Learning
Updated: April 4, 2023
Hi, this is Pinaki. I prepared the following notes for an MSc. course on cross-modal learning where I am a TA. While you can read this material if it helps you, I strongly encourage you to check the references and original papers (in the bibliography). I believe you should learn directly from the people making the inventions and not third-party like me.
Introduction
Humans perceive the world around them through multiple modalities such as images by the eyes, voices by the ears, odour by the nose, etc. While individual modalities might be incomplete or noisy, humans can naturally align and fuse information from multiple modalities to help us understand and analyse new information better. One of the core aspirations of AI is to develop algorithms that allow computers to jointly process information across modalities and utilise them to perform complex tasks like image captioning, text-guided image generation and manipulation, text-based image retrieval, and visual question-answering.
Inspired by the huge success of deep learning in language model pre-training for Natural Language Processing (NLP) with works like BERT [1], RoBERTa [2], T5 [3], and GPT-3 [4], recently there has been an increased interest in models that combine vision and language modalities (also called joint vision-language models) to learn universal cross-modal representations.
-
Cross-Modal (Vision-Language) Learning helps downstream vision tasks by providing a scalable way to learn visual representation. This is achieved by exploiting image-text pairs widely available on the web.
-
Cross-Modal (Vision Language) Learning helps downstream language tasks by enhancing language representation since “a picture is worth a thousand words”.
What we shall cover in this lecture:
-
Training Strategies for Vision-Language (VL) Models.
-
Discuss some important works in Cross-Modal (Vision Language) Learning.
-
Downstream applications of cross-modal learning, especially in sketch-based applications like abstract sketch to photo generation, adapting CLIP for generalised sketch-based image retrieval, etc.
Training Strategies for Vision-Language (VL) Models
Vision-Language models broadly comprises of 3 key elements:
-
A text encoder – the text sequence is first split into tokens and concatenated with “[CLS]” and “[SEP]” tokens, denoted as \(W = \langle [CLS], w_1, \dots, w_n, [SEP] \rangle\). Each token \(w_j\) will be mapped to a word embedding. The resulting word tokens are then encoded via a transformer-like architecture such as BERT [1].
-
An image encoder – inspired by the success of CNNs, early methods adopt CNN models like ResNet or VGGNet to extract global visual features. However, relationships among visual concepts in images are critical for VL tasks but difficult to capture from the global feature that lacks spatial information. Hence, VL literature was soon dominated by works like ViLBERT [5] and LXMERT [6] that first utilise object detectors like Faster R-CNN to detect a sequence of object regions from an image and then encode the Region-Of-Interest (RoI) features. Despite the success of detection-based visual features for VL modelling, recent works (e.g., ViT [7]) pivoted towards the simpler, faster, and end-to-end trainable grid features [8] where an image is (1) first split into several 2D patches; (2) then the embeddings of image patches are arranged in a sequence to be encoded via a transformer.
-
A strategy to fuse information – based on the way of aggregating information from vision and language modalities, we categorise the encoder into fusion encoder and dual encoder. Fusion encoders (e.g., OSCAR [9], VisualBERT [10]) employ a combination of self-attention and cross-attention operations to compute a fused representation. Although the fusion encoder could model cross-modal interactions at different levels to achieve state-of-the-art results on many VL tasks, it has to jointly encode all possible image-text pairs, which leads to an extremely slow inference speed. In contrast, dual encoders utilise two separate single-modal encoders to encode vision and language independently. Finally, it applies a shallow attention layer [11] or dot product [12] to project vision and text embedding to the same semantic space to compute similarity scores.
Important works in Cross-Modal Learning
Designing the objective function can have a great impact on what the model can learn from the multi-modal data. We discuss some popular vision-language training objectives and strategies that have been shown to perform well.
Cross-Modal Contrastive Learning
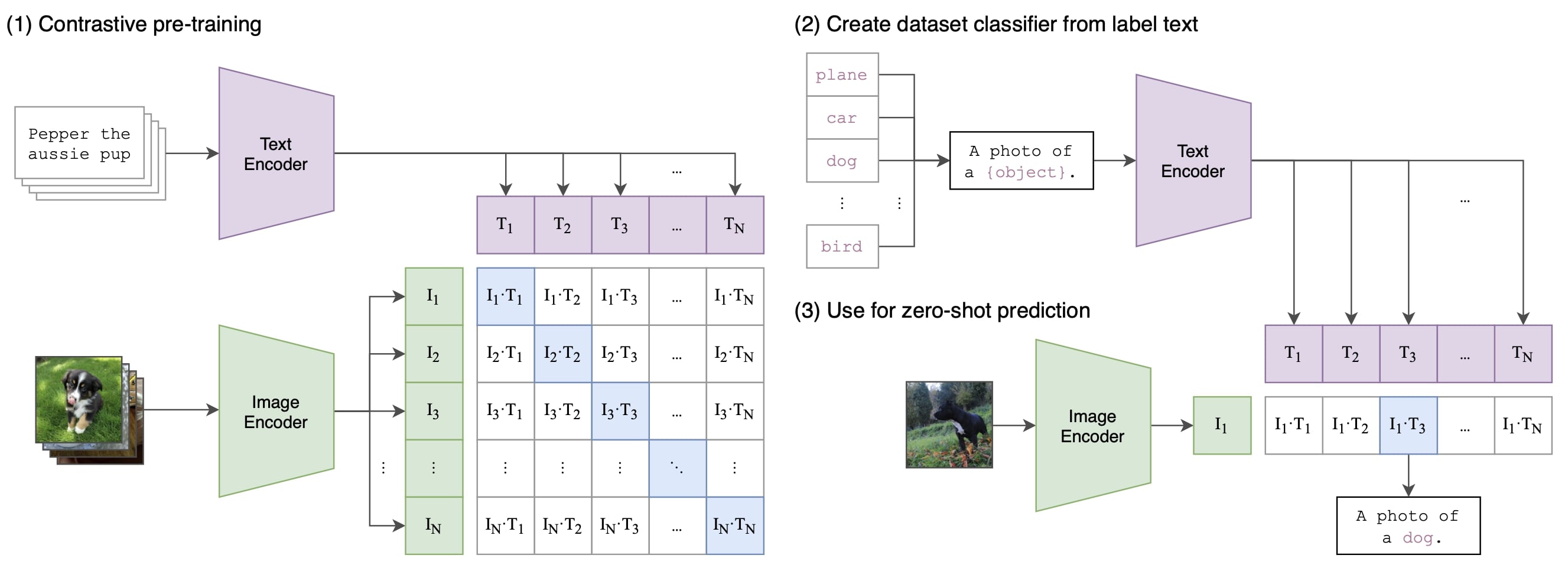
Contrastive Learning is perhaps the most popular training objective for cross-modal learning. It aims to learn a universal vision and language representation under the same semantic space such that the distance between the embeddings of image-text pairs is minimised if they match, or maximised if they do not. In the figure shown above, CLIP [12] computes the cosine distance between the text and image embeddings. Alternative contrastivel learning based methods like ALIGN [13] and DeCLIP [14] design custom distance metrics to account for noisy datasets.
An important result in CLIP [12] suggests that the aggregate supervision accessible to modern pre-training methods within web-scale collections of data surpasses that of high-quality crowd-labelled datasets. In other words, this line of work studies the pragmatic middle ground between learning from a limited amount of supervised “gold labels” and learning from practically unlimited amounts of raw data.
Enabled by the large amounts of publicly available data on the internet, the authors of CLIP created a new dataset, WebImageText (WIT), of \(400\) million (image, text) pairs and demonstrate that a simplified version of ConVIRT [15] trained from scratch, for Contrastive Language-Image Pre-training, is an efficient method of learning from natural language supervision. The resulting dataset has a similar total word count as the WebText dataset used to train GPT-2.
Cross-Modal Masked Language Modelling (MLM)
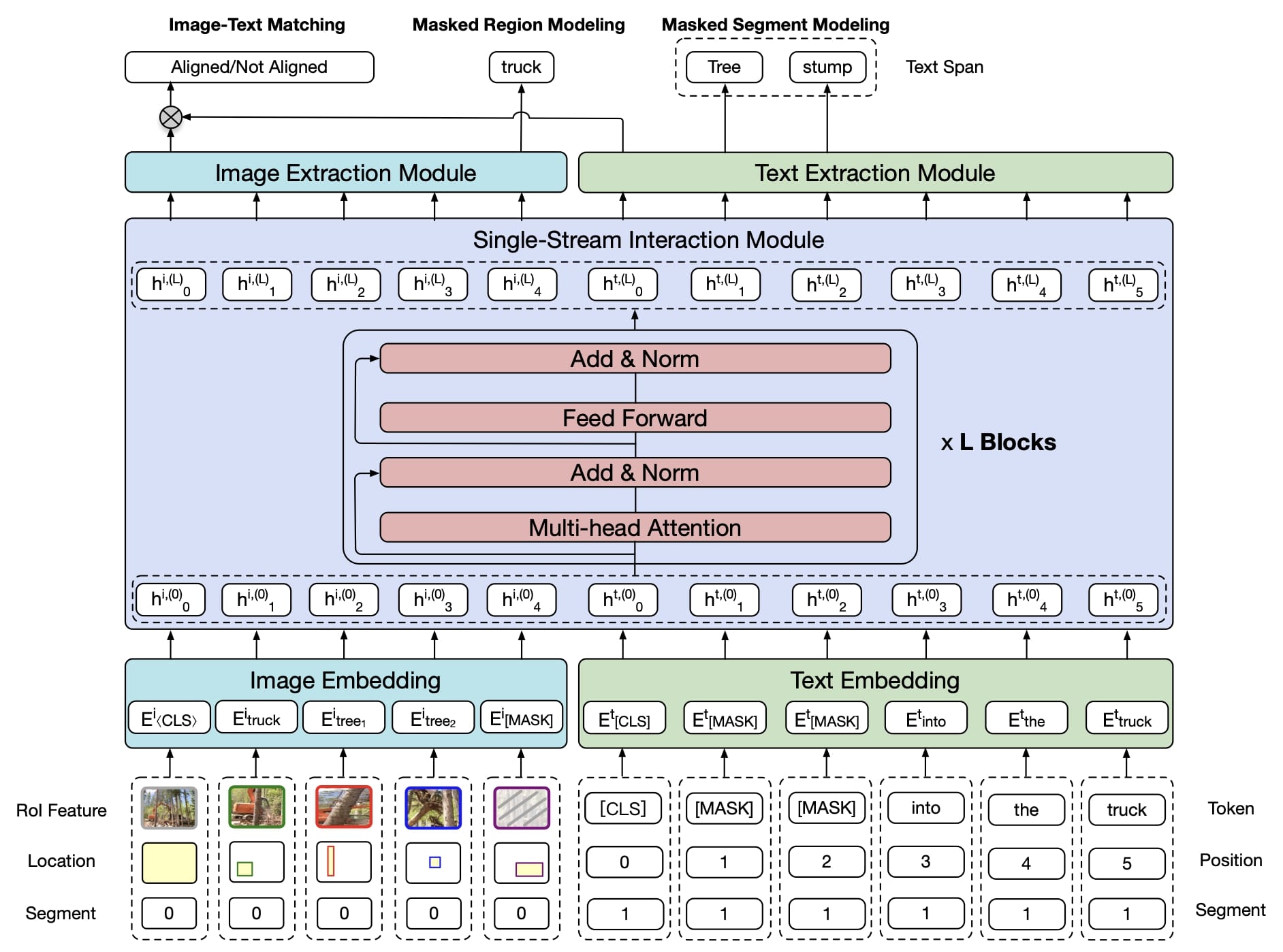
Cross-modal MLM (e.g., ViLT [16]) is similar to MLM in NLP like BERT model. In cross-modal MLM, the vision-language model predicts masked tokens not only based on unmasked tokens but also by taking vision features into account. The dependency on vision modality differentiates cross-modal MLM from MLM in NLP. It is important to note that an effective masking strategy is necessary for cross-modal MLM since if the method is too simple, the model may be able to predict the masked tokens purely based on their surrounding tokens. Masking several consecutive segments of text (e.g., InterBERT [17]) that rely on the image makes the training object more difficult and takes into account the image features.
Image-Text Matching (ITM)
While cross-modal MLM help learns the fine-grained correlation between images and text, ITM aligns them at a coarse-grained level. Given an image-text pair, ITM involves a score function \(s_{\theta}\) to measure the alignment between image and text. Some relevant works include UNITER [18] and Unicoder [19].
Downstream applications of Cross-Modal learning
Doodle It Yourself: Class Incremental Learning by Drawing a Few Sketches [20]
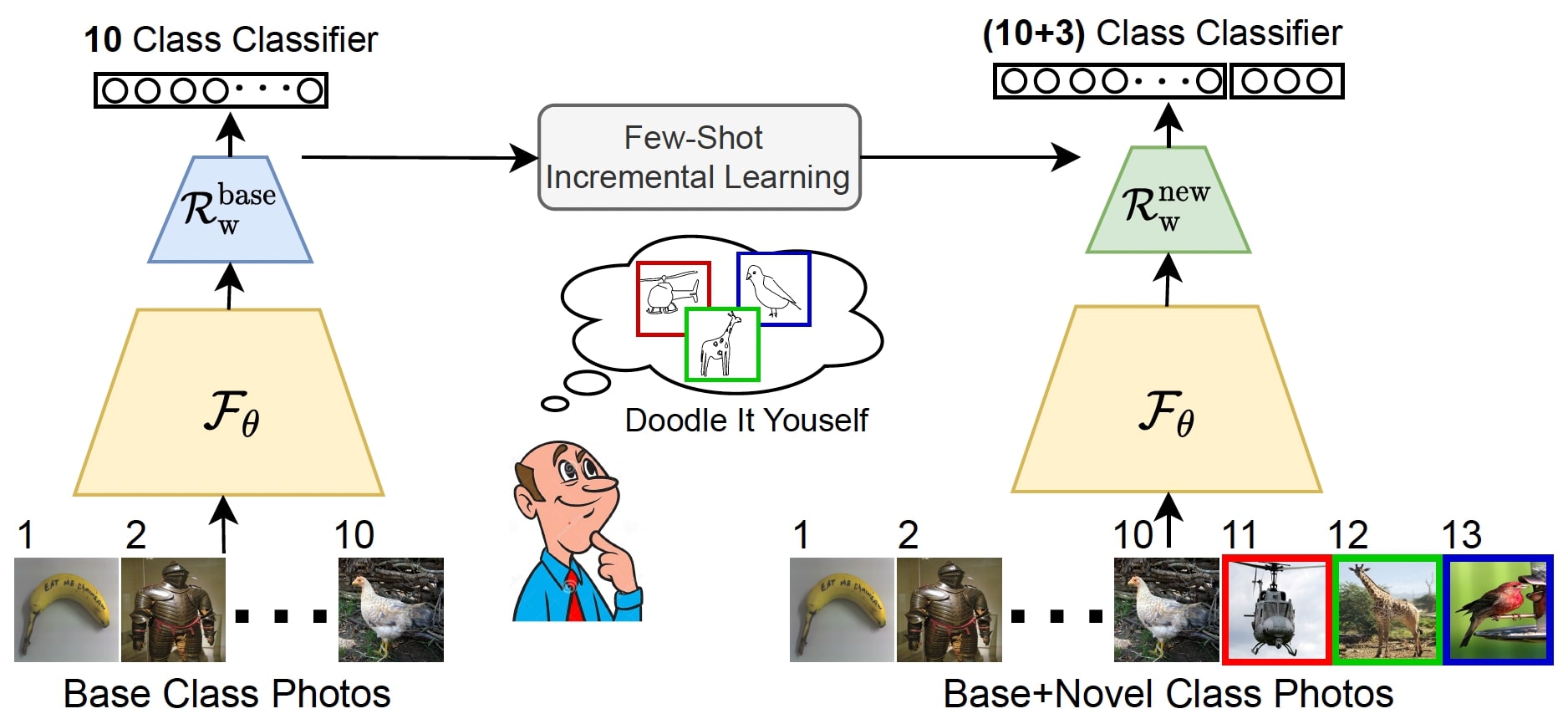
The human visual system is remarkable in learning new visual concepts from just a few examples. This is precisely the goal behind few-shot class incremental learning (FSCIL), where the emphasis is additionally placed on ensuring the model does not suffer from “forgetting”. This paper pushes the boundary further for FSCIL by addressing two key questions (1) Can the model learn from diverse modalities other than just photos (as humans do), and (2) what if photos are not readily accessible (due to ethical and privacy constraints). The key innovation lies in the use of sketches as a new modality for class support – a user can freely sketch a few examples of a novel class for the model to learn to recognise photos of that class. For instance, in the above example, given sketch exemplars (1-shot here) from 3 novel classes as support-set, a 10-class classifier gets updated to (10+3)-class classifier that can classify photos from both base and novel classes.
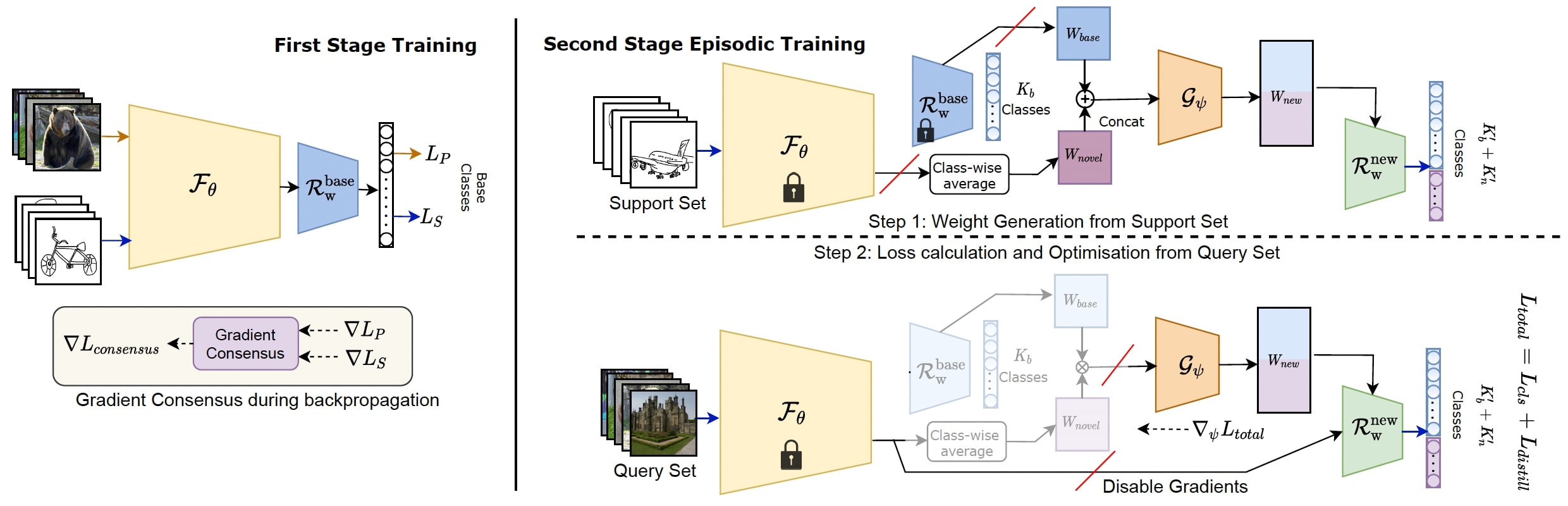
A domain-agnostic backbone feature extractor (\(\mathcal{F}_{\theta}\)) is learned through gradient consensus. In the second stage, a weight generator (\(G_{\phi}\)) is learned through episodic pseudo incremental learning involving two steps: (1) To obtain an updated [base+novel] classifier, a sketch support set is utilised to produce weight vectors for novel classes as well as to refine weight vectors for base classes. (2) For loss computation, the resulting weight vectors are evaluated against real photos from both [base+novel] classes.
Photorealistic Image Generation from Abstract Sketches [21]

Given an abstract, deformed, ordinary sketch from untrained amateurs, the model turns it into a photorealistic image, as shown in the figure above. This cross-modal (sketch-to-image synthesis) work differs significantly from prior arts in that it does not dictate an edgemap like sketch but aims to work with abstract free-hand human sketches. In doing so, the paper essentially democratises the sketch-to-photo pipeline, “picturing” a sketch regardless of how good a user sketch.
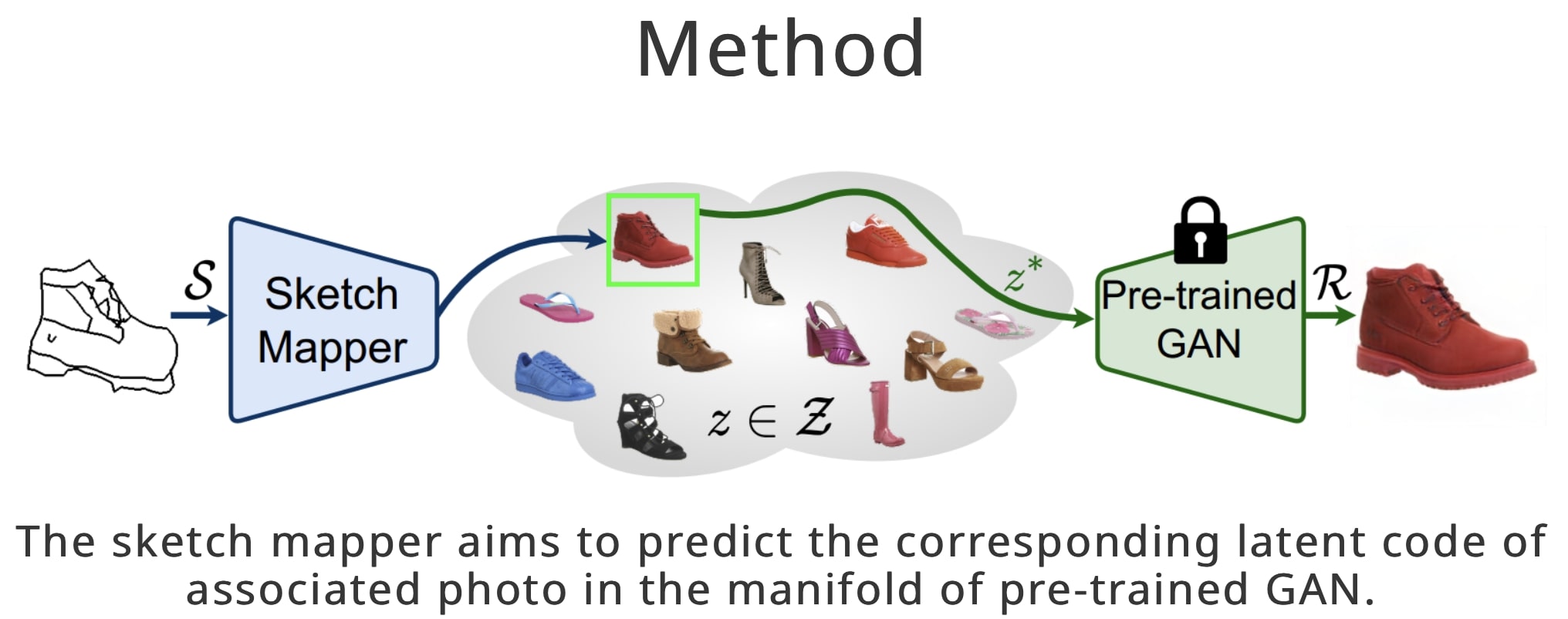
The model comprises of a decoupled encoder-decoder training paradigm, where the decoder is a StyleGAN trained on photos only. This ensures that generated results are always photo realistic. The rest is then all centred around how best to deal with the abstraction gap between sketch and photo. For that, the authors propose an autoregressive sketch mapper trained on sketch-photo pairs that map a sketch to the StyleGAN latent space.
CLIP for All Things Zero-Shot Sketch-Based Image Retrieval, Fine-Grained or Not [22]
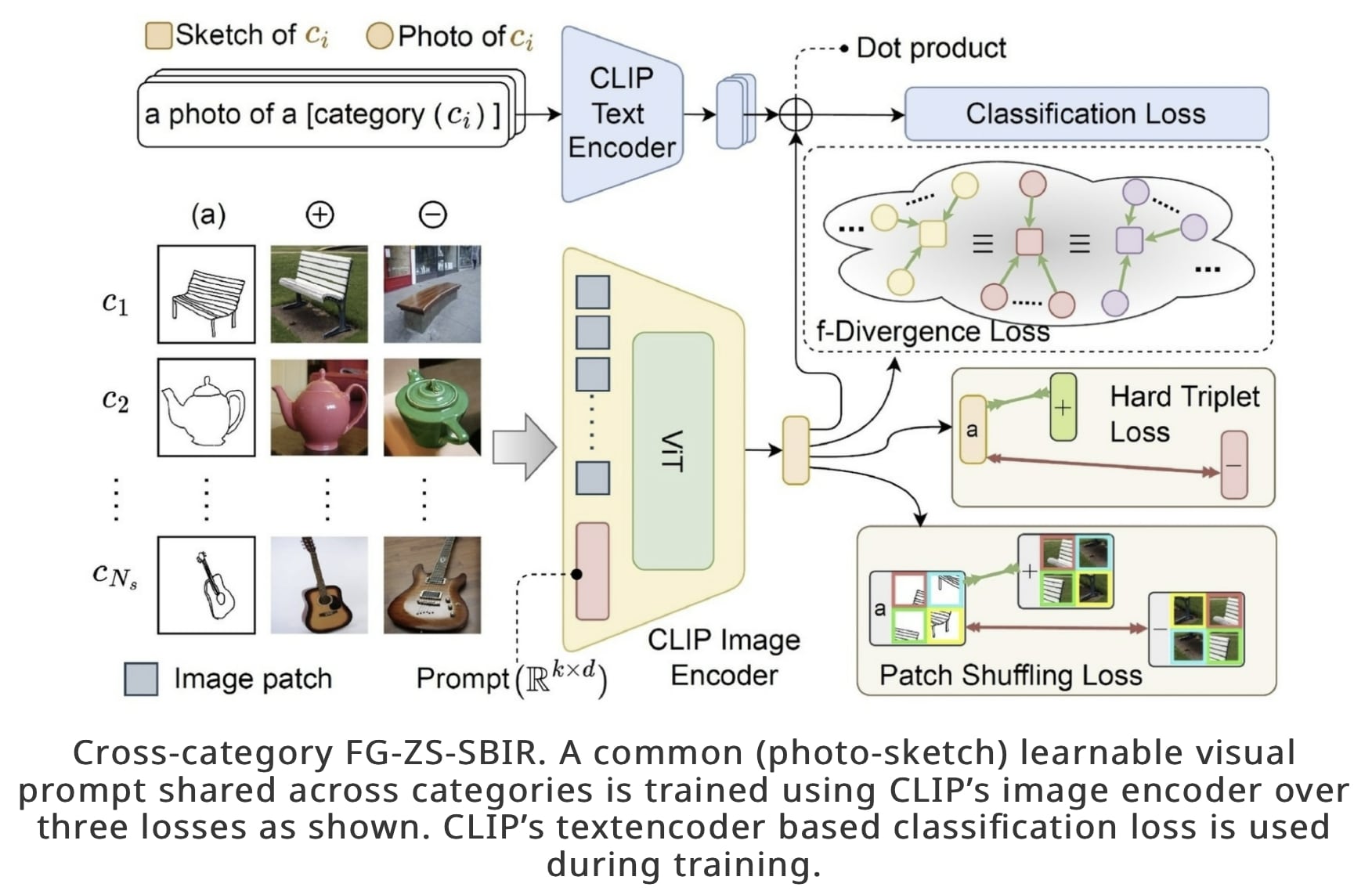
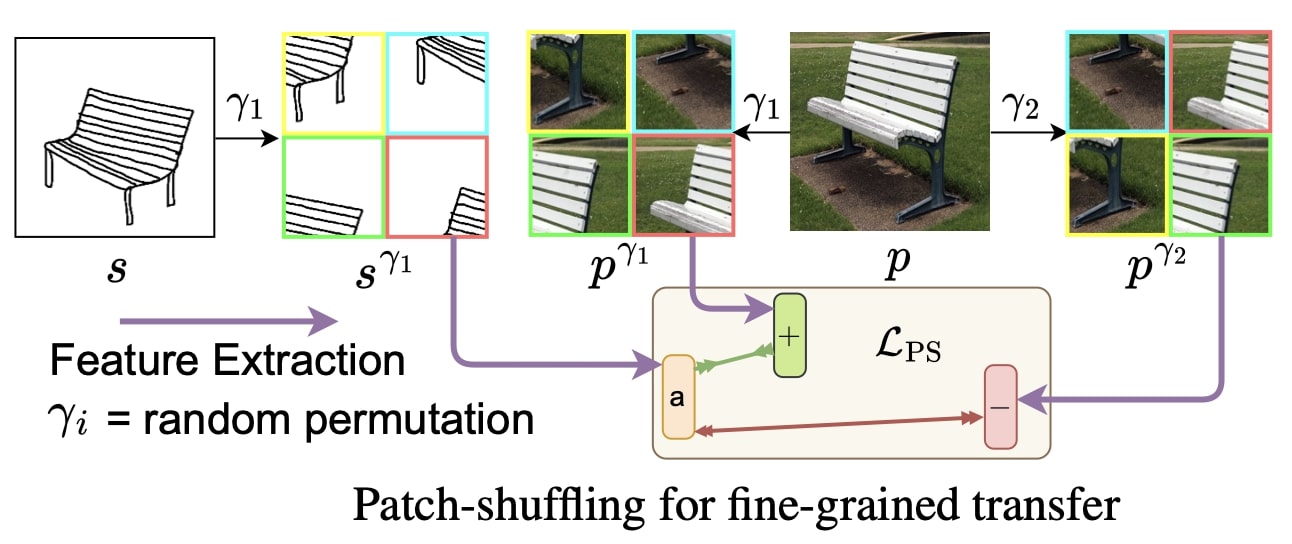
Inspired by the recent advances in foundation models and the unparalleled generalisation ability they offer, this paper leverages CLIP for zero-shot sketch-based image retrieval (ZS-SBIR). At the very core of the solution is a prompt learning setup. First, using sketch-specific prompts, the category-level ZS-SBIR overshoots all prior arts, by a large margin (\(24.8%\)) due to CLIP and ZS-SBIR synergy. For fine-grained matching, the paper uses two specific designs: (1) an additional regularisation loss to ensure the relative separation between sketches and photos is uniform across categories, which is not the case for standard standalone triplet loss, and (2) a clever path shuffling technique to help establish instance-level structural correspondences between sketch-photo pairs as shown below:
Reference
-
Y. Du, Z. Liu, J. Li, W.X. Zhao. A Survey of Vision-Language Pre-Trained Models. arXiv:2202.10936 2022.
-
Z. Gan, L. Li, C. Li, L. Wang, Z. Liu, J. Gao. Vision-Language Pre-training: Basics, Recent Advances, and Future Trends. arXiv:2210.09263 2022.
-
A Dive into Vision-Language Models – A. Dirik, S. Paul https://huggingface.co/blog/vision_language_pretraining
Bibliography
[1] J. Devlin, M.W. Chang, K. Lee, K. Toutanova. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In NAACL-HLT, 2019.
[2] Y. Liu, M. Ott, N. Goyal, J. Du, M. Joshi, D. Chen, O. Levy, M. Lewis, L. Zettlemoyer, V. Stoyanov. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv:1907.11692, 2019.
[3] C. Raffel, N. Shazeer, A. Roberts, K. Lee, S. Narang, M. Matena, Y. Zhou, W. Li, P.J. Liu. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. JMLR, 2020.
[4] T.B. Brown, B. Mann, N. Ryder, M. Subbiah, J. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, S. Agarwal, A. Herbert-Voss, G. Krueger, T. Henighan, R. Child, A. Ramesh, D.M. Ziegler, J. Wu, C. Winter, C. Hesse, M. Chen, E. Sigler, M. Litwin, S. Gary, B. Chess, J. Clark, C. Berner, S. McCandlish, A. Radford, I. Sutskever, D. Amodei. Language Models are Few-Shot Learners. arXiv:2005.14165, 2020.
[5] J. Lu, D. Batra, D. Parikh, S. Lee. ViLBERT: Pretraining Task-Agnostic Visiolinguistic Representations for Vision-and-Language Tasks. In NeurIPS, 2019.
[6] H. Tan, M. Bansal. LXMERT: Learning Cross-Modality Encoder Representations from Transformers. In EMNLP, 2019.
[7] A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, N. Houlsby. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. In ICLR, 2016.
[8] H. Jiang, I. Misra, M. Rohrbach, E. Learned-Miller, X. Chen. In Defense of Grid Features for Visual Question Answering. arXiv:2011.03615, 2020.
[9] X. Li, X. Yin, C. Li, P. Zhang, X. Hu, L. Zhang, L. Wang, H. Hu, L. Dong, F. Wei, Y. Choi, J. Gao. Oscar: Object-Semantics Aligned Pre-training for Vision-Language Tasks. In ECCV, 2020.
[10] L.H. Li, M. Yatskar, D. Yin, C.J. Hsieh, K.W. Chang. VisualBERT: A Simple and Performant Baseline for Vision and Language. arXiv:1908.03557, 2019.
[11] K.H. Lee, X. Chen, G. Hua, H. Hu, X. He. Stacked Cross Attention for Image-Text Matching. In ECCV, 2018.
[12] A. Radford, J.W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, G. Krueger, I. Sutskever. Learning Transferable Visual Models From Natural Language Supervision. In ICML, 2021.
[13] C. Jia, Y. Yang, Y. Xia, Y.T. Chen, Z. Parekh, H. Pham, Q.V. Le, Y. Sung, Z. Li, T. Duerig. Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision. In ICML, 2021.
[14] Y. Li, F. Liang, L. Zhao, Y. Cui, W. Ouyang, J. Shao, F. Yu, J. Yan. Supervision Exists Everywhere: A Data Efficient Contrastive Language-Image Pre-training Paradigm. arXiv:2110.05208, 2021.
[15] Y. Zhang, H. Jiang, Y. Miura, C.D. Manning, C.P. Langlotz. Contrastive Learning of Medical Visual Representations from Paired Images and Text. In MLHC, 2022.
[16] W. Kim, B. Son, I. Kim. ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision. In ICML, 2021.
[17] J. Lin, A. Yang, Y. Zhang, J. Liu, J. Zhou, H. Yang. InterBERT: Vision-and-Language Interaction for Multi-modal Pretraining. arXiv:2003.13198, 2020.
[18] Y.C. Chen, L. Li, L. Yu, A.E. Kholy, F. Ahmed, Z. Gan, Y. Cheng, J. Liu. UNITER: UNiversal Image-TExt Representation Learning. In ECCV, 2020.
[19] H. Huang, Y. Liang, N. Duan, M. Gong, L. Shou, D. Jiang, M. Zhou. Unicoder: A Universal Language Encoder by Pre-training with Multiple Cross-lingual Tasks. In EMNLP, 2019.
[20] A.K. Bhunia, V.R. Gajjala, S. Koley, R. Kundu, A. Sain, T. Xiang, Y.Z. Song. Doodle It Yourself: Class Incremental Learning by Drawing a Few Sketches. In CVPR, 2022.
[21] S. Koley, A.K. Bhunia, A. Sain, P.N. Chowdhury, T. Xiang, Y.Z. Song. Picture that Sketch: Photorealistic Image Generation from Abstract Sketches. In CVPR, 2023.
[22] A. Sain, A.K. Bhunia, P.N. Chowdhury, S. Koley, T. Xiang, Y.Z. Song. CLIP for All Things Zero-Shot Sketch-Based Image Retrieval, Fine-Grained or Not. In CVPR, 2023.